计算机视觉入门 1)卷积分类器 |
您所在的位置:网站首页 › 积分 种类 › 计算机视觉入门 1)卷积分类器 |
计算机视觉入门 1)卷积分类器
|
系列文章目录
计算机视觉入门 1)卷积分类器计算机视觉入门 2)卷积和ReLU计算机视觉入门 3)最大池化计算机视觉入门 4)滑动窗口计算机视觉入门 5)自定义卷积网络计算机视觉入门 6) 数据集增强(Data Augmentation)
提示:仅为个人学习笔记分享,若有错漏请各位老师同学指出,Thanks♪(・ω・)ノ 目录 系列文章目录一、卷积分类器(The Convolutional Classifer)训练分类器 二、【代码示例】汽车卡车图片分类器步骤1. 导入数据步骤2 - 定义预训练模型步骤3 - 连接头部步骤4 - 训练模型 一、卷积分类器(The Convolutional Classifer)卷积神经网络(卷积网络、CNN)是在图像分类任务上表现最好的图像分类器。 用于图像分类的卷积神经网络由两部分组成:卷积基础(convolutional base)和稠密头部(dense head): 卷积基础用于从图像中提取特征。它主要由执行卷积操作的层组成,但通常还包括其他类型的层。头部用于确定图像的类别。它主要由稠密层组成,但也可能包括其他层,如dropout层。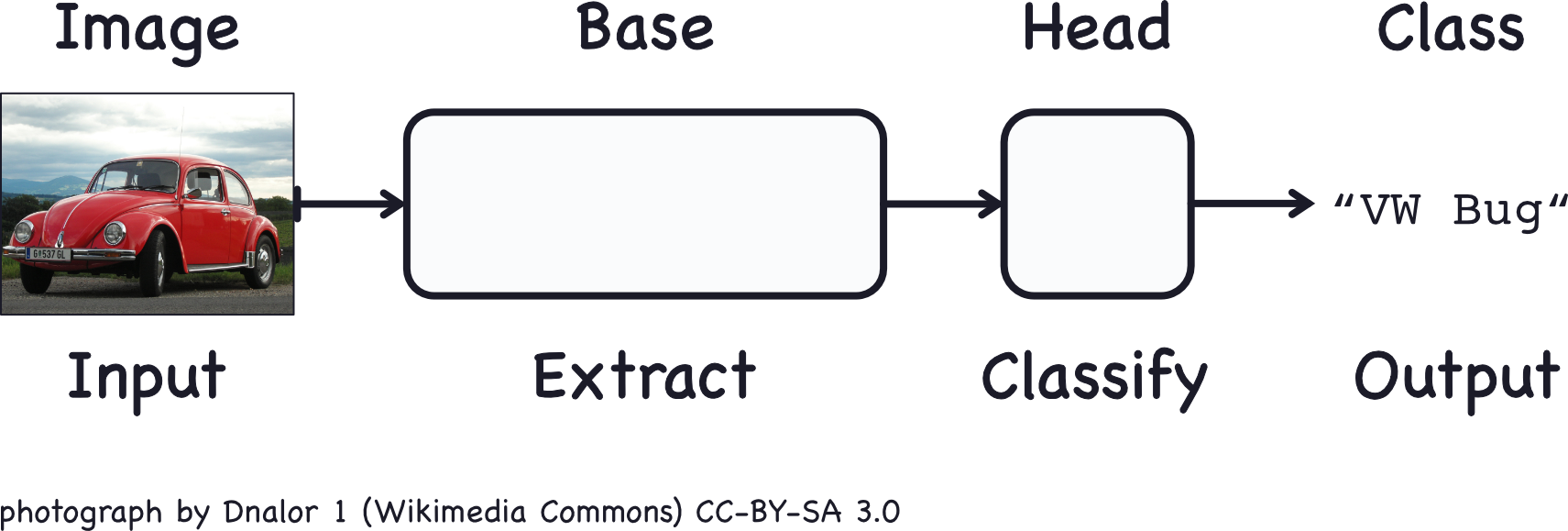
什么是视觉特征?特征可以是线条、颜色、纹理、形状、模式,或者一些复杂的组合。整个过程大致如下:
在训练过程中,神经网络的目标是学会两件事情: 从图像中提取哪些特征(基础部分),哪些特征对应于哪些类别(头部部分)。如今,卷积神经网络很少从零开始训练。更常见的做法是使用预训练模型的基础部分,然后连接一个未训练的头部。换句话说,我们是基于一个预先训练好、并且已经学会特征提取的神经网络模型,在其上面增加一些全新的层,再次训练学习分类。
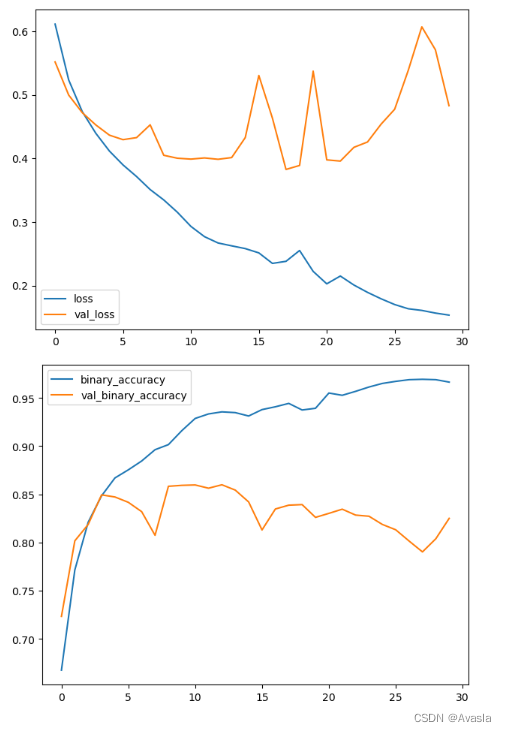
由于头部通常只包含少量的稠密层,所以即使有相对较少的数据,也可以创建出非常准确的分类器。 重用预训练模型是一种被称为迁移学习的技术。它非常有效,以至于如今几乎每个图像分类器都会使用这种技术。 二、【代码示例】汽车卡车图片分类器我们的数据集包含约一万张各种汽车的图片,大约一半是汽车,一半是卡车。 步骤1. 导入数据 # 导入所需库 import os, warnings import matplotlib.pyplot as plt from matplotlib import gridspec import numpy as np import tensorflow as tf from tensorflow.keras.preprocessing import image_dataset_from_directory # 设置随机种子以保证可复现性 def set_seed(seed=31415): np.random.seed(seed) tf.random.set_seed(seed) os.environ['PYTHONHASHSEED'] = str(seed) os.environ['TF_DETERMINISTIC_OPS'] = '1' set_seed(31415) # 设置 Matplotlib 默认参数 plt.rc('figure', autolayout=True) plt.rc('axes', labelweight='bold', labelsize='large', titleweight='bold', titlesize=18, titlepad=10) plt.rc('image', cmap='magma') warnings.filterwarnings("ignore") # 以清理输出单元格中的警告信息 # 加载训练集和验证集 ds_train_ = image_dataset_from_directory( '../input/car-or-truck/train', labels='inferred', label_mode='binary', image_size=[128, 128], interpolation='nearest', batch_size=64, shuffle=True, ) ds_valid_ = image_dataset_from_directory( '../input/car-or-truck/valid', labels='inferred', label_mode='binary', image_size=[128, 128], interpolation='nearest', batch_size=64, shuffle=False, ) # 数据处理流程 def convert_to_float(image, label): image = tf.image.convert_image_dtype(image, dtype=tf.float32) return image, label AUTOTUNE = tf.data.experimental.AUTOTUNE ds_train = ( ds_train_ .map(convert_to_float) .cache() .prefetch(buffer_size=AUTOTUNE) ) ds_valid = ( ds_valid_ .map(convert_to_float) .cache() .prefetch(buffer_size=AUTOTUNE) ) 步骤2 - 定义预训练模型最常用于预训练的数据集是 ImageNet,这是一个包含许多自然图像的大型数据集。Keras 在其 applications 模块 中包含了多种在 ImageNet 上预训练过的模型。我们将使用的预训练模型是 VGG16。 pretrained_base = tf.keras.models.load_model( '../input/cv-course-models/cv-course-models/vgg16-pretrained-base', ) pretrained_base.trainable = False以上代码加载了预训练的VGG16模型,并将其设置为不可训练(trainable = False)。这是迁移学习中常用的做法,通过重用已经在大规模数据集上训练过的模型,可以提取出图像的有用特征,从而在少量数据上构建准确的分类器。 步骤3 - 连接头部接下来,我们要连接分类器的头部部分。在这个示例中,我们将使用一层隐藏单元(第一个 Dense 层),然后是一层将输出转换为类别1(Truck)的概率分数的层。Flatten 层将基础部分的二维输出转换为头部所需的一维输入。 from tensorflow import keras from tensorflow.keras import layers model = keras.Sequential([ pretrained_base, # 加载的VGG16模型,用于从图像中提取特征。 layers.Flatten(), # 将提取的特征展平,以便送入后续的全连接层。 layers.Dense(6, activation='relu'), # 6个神经元的隐藏层,使用ReLU激活函数。 layers.Dense(1, activation='sigmoid'), # 输出层,包含一个神经元,使用Sigmoid激活函数。 ]) 步骤4 - 训练模型由于这是一个两类问题,我们将使用二进制版本的 crossentropy 和 accuracy 作为损失函数和评估指标。通常情况下,adam 优化器表现较好,所以我们也选择了它。 model.compile( optimizer='adam', loss='binary_crossentropy', metrics=['binary_accuracy'], ) history = model.fit( ds_train, validation_data=ds_valid, epochs=30, verbose=0, )在训练神经网络时,检查损失和指标的图表始终是一个好的做法。history 对象包含了这些信息,可以通过 history.history 字典来获取。我们可以使用 Pandas 将这个字典转换为数据框,并使用内置方法进行绘制。 import pandas as pd history_frame = pd.DataFrame(history.history) history_frame.loc[:, ['loss', 'val_loss']].plot() history_frame.loc[:, ['binary_accuracy', 'val_binary_accuracy']].plot();结果输出: |
 (实际提取的特征看起来可能略有不同,但这基本思想一致。)
(实际提取的特征看起来可能略有不同,但这基本思想一致。)
【本文地址】